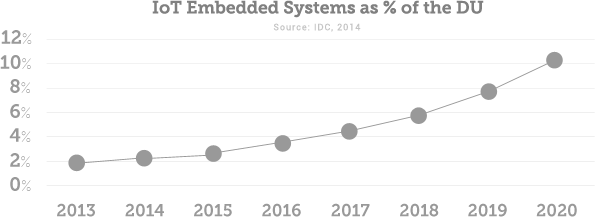
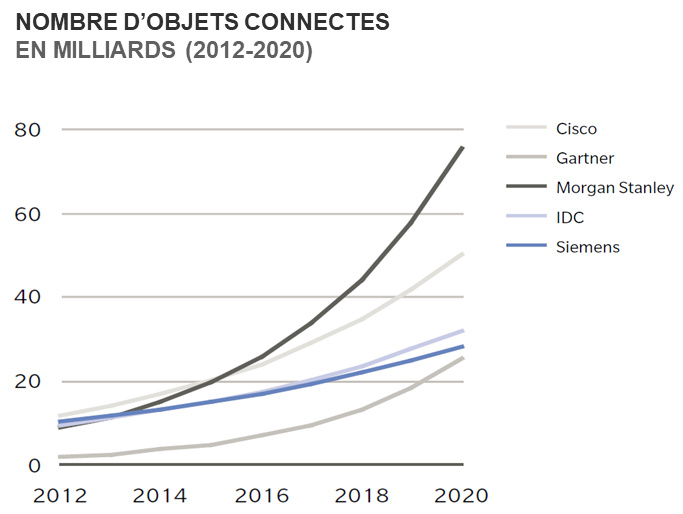
Il y a quelques mois, ma curiosité m’a poussé à investir quelques kopecks dans les devises virtuelles. A ce moment je n’avais qu’une vague idée de ce que j’achetais vraiment et plusieurs questions se sont imposées à moi. Pourquoi certaines cryptomonnaies ont-elles une valeur plus élevée que d’autres ? Qu’est-ce qui différencie la valeur d’une pièce d’or d’un jeton électronique ? Peut-on objectivement estimer la valeur d’un Bitcoin ? En persévérant et en retournant ces questions, j’en suis arrivé à des éléments réponses. Et entre temps, j’ai arrêté d’investir dans les cryptomonnaies !
Sommaire
1 – Valeur et complexité
2 – Théorie de la valeur
3 – L’analogie de la Mine d’or
4 – Le Bitcoin vaut-il 233 euros ?
5 – Conclusion
Valeur et complexité
Commençons par une citation. Et pas de n’importe qui ! Jean-Paul Delahaye est un informaticien-mathématicien et enseignant-chercheur français. Reconnu comme l’un des premiers à avoir vulgarisé le fonctionnement du Bitcoin en France, il est un fin connaisseur de la cryptomonnaie. Fin 2017 il écrivait cette phrase sur son blog :
« Le bitcoin tient parce que la profondeur logique de sa blockchain est grande et s’accroît au fur et à mesure qu’on calcule des SHA256 […] le bitcoin repose sur quelque chose de matériel ou de quasi-matériel : du contenu en calcul »
De quoi est fait le Bitcoin?, octobre 2017
Décortiquons-la.
Le début est simple. Le terme « Bitcoin tient » signifie tout simplement que la blockchain Bitcoin fonctionne de manière autonome et sans accros. « Ça roule Raoul » aurait pu convenir mais n’a pas été retenu par l’auteur.
La suite est un peu plus compliquée avec deux termes liés : le « contenu en calcul » et « la profondeur logique ».
Ce qu’on appelle le « contenu en calcul » ce sont des résultats numériques qui se suivent et qui sont stockés dans une blockchain. Sans rentrer dans l’explication de comment les blocs sont mathématiquement liés les uns aux autres, il est plus simple de prendre l’exemple d’une suite arithmétique classique. Si l’on considère les dix premiers termes de la suite de Fibonacci mis bout-à-bout nous avons « 0112358132134″. Cette suite de nombres accolés est en fait très comparable à une blockchain puisque qu’elle n’est pas aléatoire et reflète bien du contenu calculé selon la formule de progression de la suite. La chaîne numérique « 5647684534123418 » que j’ai tapé aléatoirement sur mon clavier ne semble pas refléter une quelconque progression mathématique. Elle n’est donc pas comparable à une blockchain a priori.
L’idée de « profondeur logique » est moins évidente et se rapproche de ce que l’on nomme complexité en mathématiques. La complexité est une mesure à la fois de la difficulté d’obtention d’un résultat ainsi que son caractère d’incompressibilité. Si l’on reprend l’exemple de la suite de Fibonacci, le n-ième terme est calculé par la formule F(n)=F(n-1)+F(n-2) que je qualifie de simple car le calcul s’effectue rapidement avec des termes F(n) relativement courts. Si l’on considère maintenant une suite définie par C(n)=C(n-1)^[100*C(n-2)]! le calcul devient plus délicat. Non seulement l’effort calculatoire est exponentiel à chaque itération mais on se retrouve rapidement avec des termes extrêmement longs. On peut dire avec les mains que la chaîne numérique « F(1)F(2)…F(100) » est moins complexe que la chaîne numérique « C(1)C(2)…C(100) ». Comparer la profondeur logique de deux chaînes numériques construites à partir de deux algorithmes différents est finalement assez simple à appréhender. Encore plus simple, si l’on considère seulement F(n) et que l’on compare les chaînes [[F(1);F(50)]] et [[F(1);F(1000)]] on remarque que la première est plus courte et plus facile à obtenir. L’idée de la correspondance entre complexité et longueur de chaîne pour un même algorithme émerge donc très naturellement.
Dernière précision. Le calcul arithmétique dans Bitcoin n’est pas engendré par une suite arithmétique traditionnelle mais par un algorithme dit de cryptage asymétrique appelé SHA256. Asymétrique signifie que calculer l’image de la fonction est difficile mais que l’opération inverse, à savoir vérifier que son antécédent correspond bien à l’image, est simple. Voilà pour la présentation des termes.
On recolle les morceaux !
Résumons les propos de Delahaye en trois points : (1) La complexité d’une blockchain augmente avec le temps (« la profondeur logique de sa blockchain s’accroît ») puisque son contenu en calcul grandit avec les transactions. (2) La complexité c’est donc une mesure de la difficulté pour obtenir cette blockchain. Plus elle est complexe plus il est difficile de la contrefaire – puisqu’il y a plus de contenu à falsifier. (3) La capacité d’une blockchain à croître de manière autonome et sans être falsifiée (« elle tient ») est une source de valeur. En effet cela démontre la robustesse du système, sa résilience.
En résumé : la complexité du calcul que renferme une blockchain est une mesure de sa valeur. Pourquoi est-ce intéressant ? Parce que la complexité est un critère objectif et intrinsèque propre à n’importe quelle blockchain : les comparer devient simple. De plus la complexité se révèle être un excellent indicateur de confiance. Si l’on s’autorise quelques approximations, la complexité d’une blockchain est sa taille informatique, tout simplement. Pour deux algorithmes de hash comparables du moins. Rappelez-vous de l’exemple de la suite de Fibonacci.
A retenir
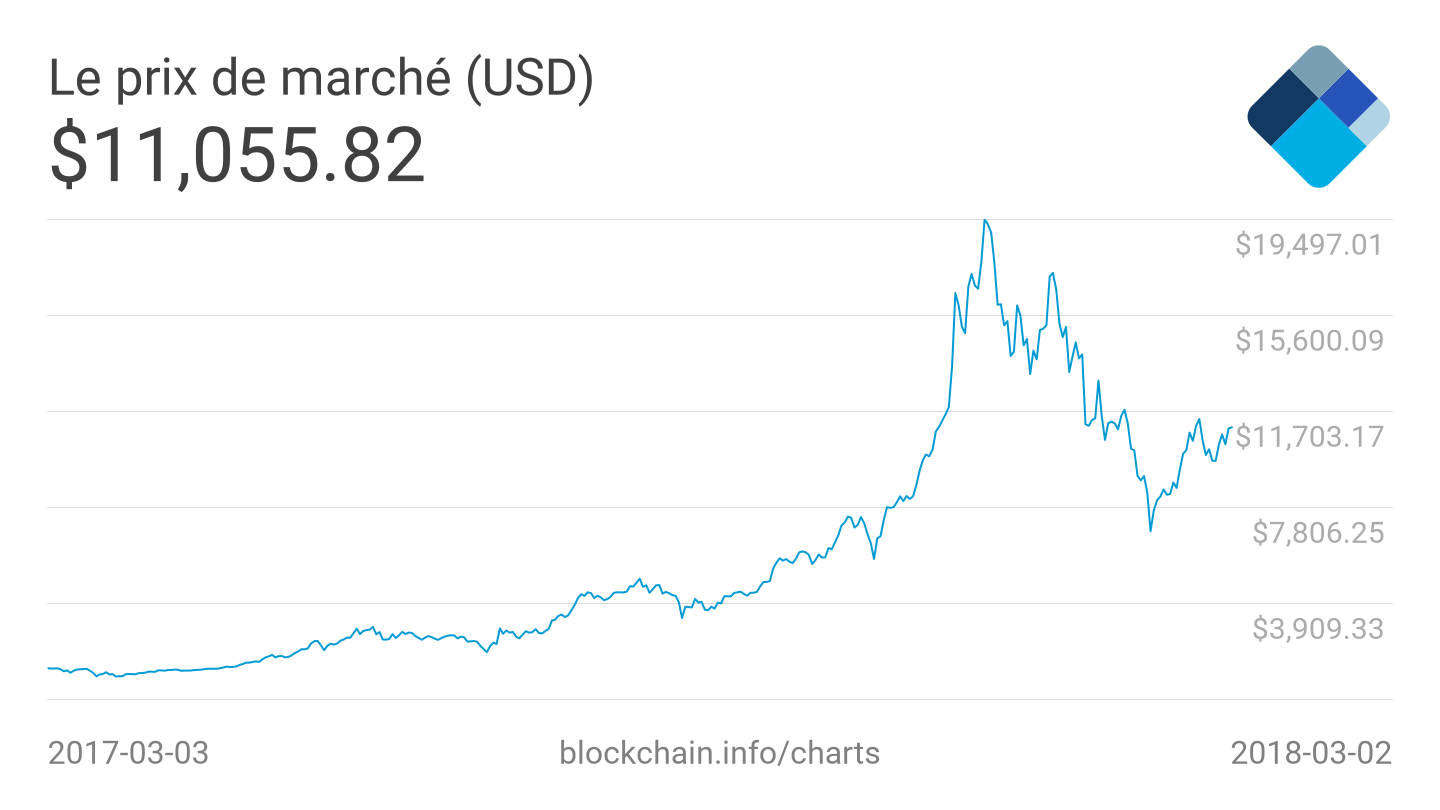
Plus une blockchain est longue, plus elle est issue d’un effort de calcul important, plus elle est mathématiquement sécurisée. Il est donc raisonnable de lui affecter plus de valeur. Par ce principe il devient possible de comparer la valeur des blockchains rien qu’en comparant leurs tailles.
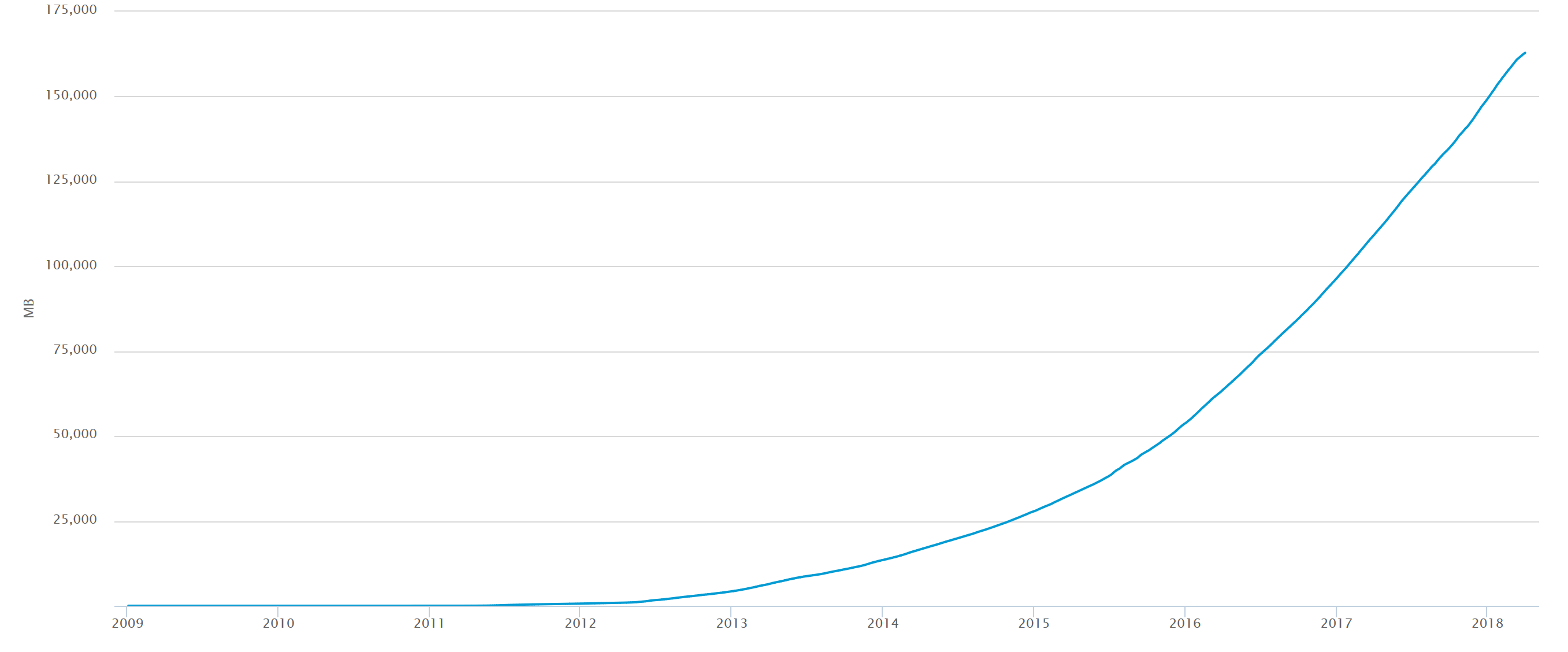
La blockchain Bitcoin grandit de manière quasi-exponentielle avec le temps, blockchain.info, avril 2018
Pour autant, l’idée de valeur reste floue et mérite d’être discutée plus en détails.
Théorie de la valeur
La question de la valeur d’une cryptomonnaie est essentielle puisque la théorie économique admet plusieurs définitions de ce qu’on appelle valeur. A ce propos, le billet du philosophe Thomas Schauder La valeur des choses dépend-elle de leur prix ? (Le Monde, janvier 2018) dresse une comparaison éclairante et accessible entre la valeur d’usage et la valeur d’échange, deux manières classiques d’aborder la notion.
Pourtant dans notre cas, la valeur attribuée à la taille d’une blockchain n’est ni sa valeur d’usage, puisque la monnaie est un objet avec peu de praticité, ni sa valeur d’échange, puisque celle-ci est fixée par le marché. Il s’agit d’une valeur objective de l’effort nécessaire pour aboutir à cette chaîne, une valeur d’obtention en quelque sorte. Considérer l’ensemble de l’effort utile pour arriver à la blockchain(1) revient grosso modo à comptabiliser l’ensemble des coûts électriques associés aux calculs cryptographiques depuis la première transaction, qui sont appelés communément « coûts de minage » par la communauté blockchain(2).
A retenir
La valeur intrinsèque d’une blockchain est équivalente au coût électrique associé à l’effort de minage. Ce coût est différent de sa valeur marchande.
(1) par « effort utile » je signifie que les contributions « perdantes » dans la compétition de minage ne sont pas à comptabiliser. En effet, bien qu’ayant eu lieu leurs traces ne subsistent pas dans la chaîne principale et ne participent donc pas à la complexité de l’objet. Elles ne sont donc pas « utiles ». Par définition, tout calcul basé sur une estimation sans distinction de la consommation électrique du minage est de fait surévaluée.
(2) ce calcul est approximatif puisque l’on a négligé les contributions matérielles (hardware) et humaines (développement informatique) aux coûts difficilement évaluables mais vraisemblablement très minoritaires.
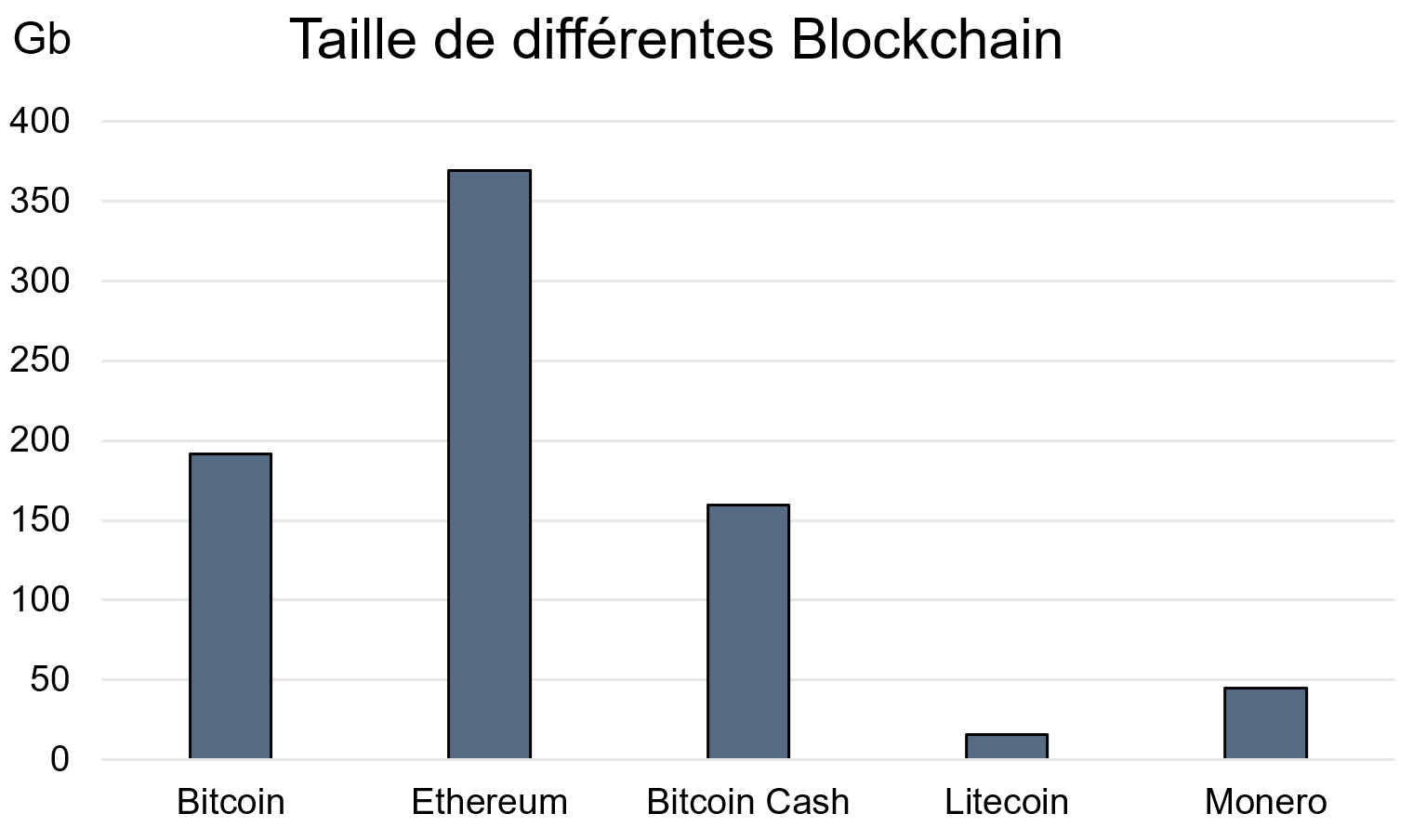
L’Ethereum est la Blockchain la plus lourde en avril 2018, bitinfocharts.com
L’analogie de la mine d’or
Dès 2009 la connexion entre valeur et coût électrique est relevée par le fondateur du Bitcoin, Satoshi Nakamoto ! Il établit une analogie intéressante entre l’extraction de l’or et le coût du calcul cryptographique pour une cryptomonnaie.
En effet, l’exploitation d’un métal précieux à partir de minerais souterrains nécessite, un effort qui est quantifiable et qui peut être ramené à un coût d’exploitation. Rappelons que ce coût pour la découverte, l’extraction et le raffinage du métal précieux est différent de sa valeur d’échange qui dépend seulement du cours du marché (la demande rapportée à l’offre). Tant que ce coût d’exploitation ou d’obtention est inférieur au cours du marché (35 k€/kg d’or en 2018) il est économiquement viable d’exploiter une mine d’or puisque la revente assure une plus-value. De la même manière pour une cryptomonnaie, que tant que les coûts pour effectuer ces calculs sont inférieur au cours de la devise virtuelle, il est intéressant de prendre part à l’effort calculatoire pour assurer son bon fonctionnement. On construit sur la base de cette analogie le mot minage renvoyant à l’effort mis en œuvre pour le calcul.
Ce que l’on sait moins, c’est que les règles à la base du fonctionnement du Bitcoin favorisent l’apparition de cette situation. Id est favoriser un coût de minage inférieur au cours du marché pour inciter les mineurs à fournir de la puissance de calcul et maintenir le réseau fonctionnel.
A retenir
Il est viable de miner pour le compte d’une blockchain si les coûts électriques associés à la compétition de minage sont inférieurs au cours du marché. Un mécanisme existe pour favoriser cette situation.
Le Bitcoin vaut-il 233 euros ?
Avec toutes les considérations abordées plus haut, il devient possible de mettre en place des indicateurs simples et de mener des calculs de valeur.
La valeur unitaire moyenne d’un jeton
On appelle jeton, l’unité monétaire d’une cryptomonnaie. Son coût d’obtention moyen est défini comme la valeur du calcul de la blockchain ramené au nombre de jeton en circulation. Puisque la quantité de calcul croît à chaque transaction, son coût d’obtention croît également pour un volume de jeton fixe, puisque la plupart des blockchains ont une émission de jetons très progressive au cours du temps.
VUMJ = valeur du calcul de la blockchain / nombres de jetons en circulation
A quelques approximations près, on trouve qu’un BTC renferme 233€ de travail calculatoire contre 27,64€ pour un ETH. Il est a priori justifié que le cours du BTC soit supérieur à celui de l’ETH sur l’argument objectif de la confiance.
(Edit 08/08/2018)
Ce résultat est basé sur l’estimation annuelle publiée par Digiconomist des coûts de minage ainsi qu’au taux euro-dollars à la date d’écriture de l’article (juin 2018). L’hypothèse principale est que ce coût a augmenté quasi-exponentiellement sur la période non couverte par l’estimation du site. On néglige également la variation du nombre de Bitcoin sur la période. Pour le détail de ce calcul, je vous invite à consulter la section commentaires.
VUMJ (BTC) = (3,55b$ + 1,09b$)/ 17,1 millions = 233€
VUMJ (ETH) = (2,4b$ + 0,81b$) / 100 millions = 27,64€
La valeur d’obtention rapportée au cours du marché
La valeur des marchés est une valeur subjective et humaine qui fixe le prix des choses. Ainsi une baguette de pain à 1,5€ vaut probablement des dizaines de fois son prix de revient, qui est essentiellement donné par le prix de sa matière première (farine, eau, levure) et du travail pour l’obtenir (transport, stockage, cuisson, frais). L’iPhone 8 Plus est vendu $799 par Apple avec un coût de revient estimé à $295 soit 50% de marge à chaque produit vendu. Pour autant, il n’existe aucune règle générale entre ces deux coûts si ce n’est que l’on cherche en principe à maximiser les marges et qu’il est interdit de vendre à perte.
Dernier exemple. Le prix d’extraction de l’or est d’environ $919 par once alors que son cours est approximativement de $1 270. Le rapport donne une marge de 38%.
A retenir
On a calculé un coût de revient de 233€ pour le Bitcoin alors que son cours évolue à 5 400€. La marge est de 2 320%. Pour Ethereum est sensiblement plus bas avec un coût de revient de 27,64€ et un cours à 375€. La marge est cette fois-ci de 1 360%. A chacun de se faire sa propre opinion.
Conclusion
En introduction nous nous demandions Pourquoi certaines cryptomonnaies ont-elles une valeur plus élevée que d’autres ? On sait maintenant que la valeur de revient d’une cryptomonnaie provient uniquement du nombre d’informations mathématiques qu’elle contient grâce à des milliards de transistors qui travaillent sans relâche de la matière électrique pour la transformer en matière arithmétique. Qu’est-ce qui différencie la valeur d’une pièce d’or d’un jeton électronique ? Finalement pas grand chose, les deux tirent leur valeur de leur rareté. Si ce n’est que dans un cas les pièces d’or ont une existence palpable avec une valeur d’usage faible. Leurs coûts d’obtention provient du travail de la terre dans les carrières pour en extraire le précieux métal. Un jeton de cryptomonnaie comme le Bitcoin n’a lui pas d’existence physique, ce n’est que mathématique et informatique pour une valeur d’usage nulle. Leur coût d’obtention provient de la création ex nihilo de la monnaie par des règles de minage communément acceptées. Peut-on objectivement estimer la valeur d’un Bitcoin ? Oui et non. On ne peut pas anticiper la fluctuation des valeurs d’échange des Bitcoins. L’offre et la demande sur les marchés ne peuvent évidemment pas se prévoir, sauf délits d’initiés. En revanche, on peut calculer objectivement le coût d’obtention d’un BTC, quantité à rapprocher de la notion de valeur-travail au sens marxiste (taskforce). Une comparaison au cours du marché est rendue possible mais n’éclairera que partiellement.
A retenir
La valeur marchande des choses ne dépend que de la valeur que l’on veut bien leur donner. A vous de croire, ou ne pas croire.